网卡性能优化
运行在操作系统内核态的网卡驱动程序基本都是基于异步中断处理模式,而DPDK采用了轮询或者轮询混杂中断的模式来进行收包和发包。DPDK起初的纯轮询模式是指收发包完全不使用任何中断,集中所有运算资源用于报文处理。但这不是意味着DPDK不可以支持任何中断。根据应用场景需要,中断可以被支持,最典型的就是链路层状态发生变化的中断触发与处理。
任何包进入到网卡,网卡硬件会进行必要的检查、计算、解析和过滤等,最终包会进入物理端口的某一个队列。物理端口上的每一个收包队列,都会有一个对应的由收包描述符组成的软件队列来进行硬件和软件的交互,以达到收包的目的。DPDK的轮询驱动程序负责初始化好每一个收包描述符,其中就包含把包缓冲内存块的物理地址填充到收包描述符对应的位置,以及把对应的收包成功标志复位。然后驱动程序修改相应的队列管理寄存器来通知网卡硬件队列里面的哪些位置的描述符是可以有硬件把收到的包填充进来的。网卡硬件会把收到的包一一填充到对应的收包描述符表示的缓冲内存块里面,同时把必要的信息填充到收包描述符里面,其中最重要的就是标记好收包成功标志。当一个收包描述符所代表的缓冲内存块大小不够存放一个完整的包时,这时候就可能需要两个甚至多个收包描述符来处理一个包。 每一个收包队列,DPDK都会有一个对应的软件线程负责轮询里面的收包描述符的收包成功的标志。一旦发现某一个收包描述符的收包成功标志被硬件置位了,就意味着有一个包已经进入到网卡,并且网卡已经存储到描述符对应的缓冲内存块里面,这时候驱动程序会解析相应的收包描述符,提取各种有用的信息,然后填充对应的缓冲内存块头部。然后把收包缓冲内存块存放到收包函数提供的数组里面,同时分配好一个新的缓冲内存块给这个描述符,以便下一次收包。
每一个发包队列,DPDK都会有一个对应的软件线程负责设置需要发送出去的包,DPDK的驱动程序负责提取发包缓冲内存块的有效信息,例如包长、地址、校验和信息、VLAN配置信息等。DPDK的轮询驱动程序根据内存缓存块中的包的内容来负责初始化好每一个发包描述符,驱动程序会把每个包翻译成为一个或者多个发包描述符里能够理解的内容,然后写入发包描述符。发包的轮询就是轮询发包结束的硬件标志位。DPDK驱动程序根据需要发送的包的信息和内容,设置好相应的发包描述符,包含设置对应的RS标志,然后会在发包线程里不断查询发包是否结束。当驱动程序发现写回标志,意味着包已经发送完成,就释放对应的发包描述符和对应的内存缓冲块,这时候就全部完成了包的发送过程。
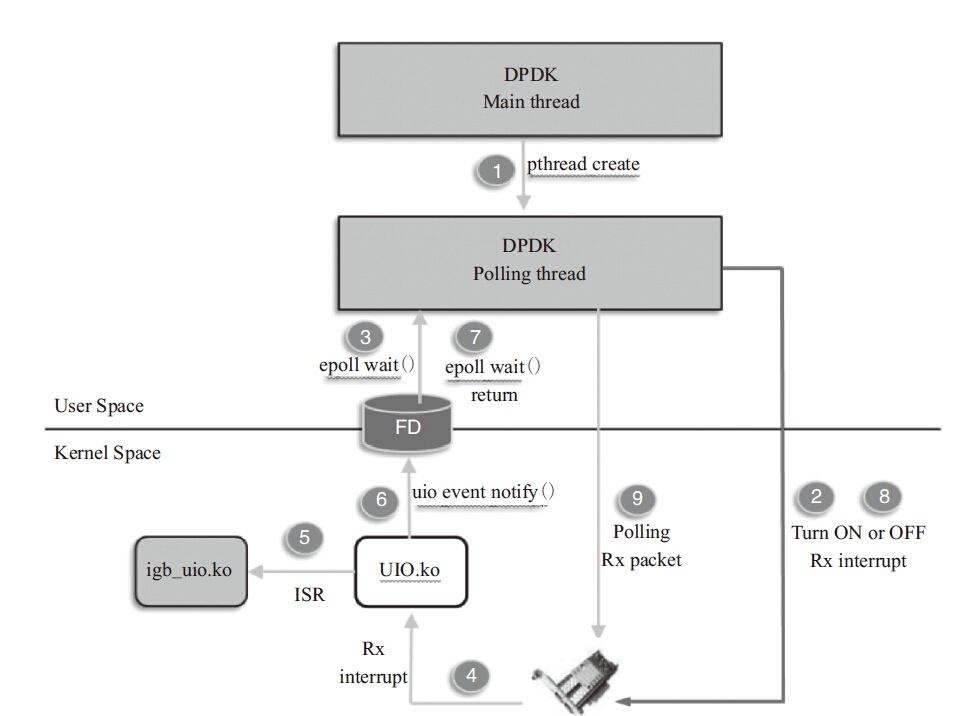
由于实际网络应用中可能存在的潮汐效应,在某些时间段网络数据流量可能很低,甚至完全没有需要处理的包,这样就会出现在高速端口下低负荷运行的场景,而完全轮询的方式会让处理器一直全速运行,明显浪费处理能力和不节能。因此在DPDK R2.1和R2.2陆续添加了收包中断与轮询的混合模式的支持。例子程序l3fwd-power,使用了DPDK支持的中断加轮询的混合模式。应用程序开始就是轮询收包,这时候收包中断是关闭的。但是当连续多次收到的包的个数为零的时候,应用程序定义了一个简单的策略来决定是否以及什么时候让对应的收包线程进入休眠模式,并且在休眠之前使能收包中断。休眠之后对应的核的运算能力就被释放出来。当后续有任何包收到的时候,会产生一个收包中断,并且最终唤醒对应的应用程序收包线程。线程被唤醒后,就会关闭收包中断,再次轮询收包。
性能优化
- Burst收发包就是DPDK的优化模式,它把收发包复杂的处理过程进行分解,打散成不同的相对较小的处理阶段,把相邻的数据访问、相似的数据运算集中处理。这样就能尽可能减少对内存或者低一级的处理器缓存的访问次数,用更少的访问次数来完成更多次收发包运算所需要数据的读或者写(参考
rte_eth_rx_burst()和rte_eth_tx_burst())。 - 利用CPU指令乱序多发的能力,批量处理无数据前后依赖关系的独立事务,可以掩藏指令延迟。对于重复事务执行,通常采用循环逐次操作。对于较复杂事务,编译器很难大量地去乱序不同迭代序列下的指令。为了达到批量处理下乱序时延隐藏的效果,常用的做法是在一个序列中铺开执行多个事务,以一个合理的步进迭代。
- 利用Intel SIMD指令进一步并行化包收发。
- 大页:例如,增加内核启动参数“default_hugepagesz=1G hugepagesz=1G hugepages=8”来配置好8个1G的大页。
- DPDK的软件线程一般都需要独占一些处理器的物理核或者逻辑核来完成稳定和高性能的包处理,如果硬件平台的处理器有足够多的核,一般都会预留出一些核来给DPDK应用程序使用。例如,增加内核启动参数“isolcpus=2,3,4,5,6,7,8”,使处理器上ID为2,3,4,5,6,7,8的逻辑核不被操作系统调度。
- 修改编译参数来使能“extended tag”:
CONFIG_RTE_PCI_CONFIG=y,CONFIG_RTE_PCI_EXTENDED_TAG="on". - DPDK参数
- 收包队列长度:DPDK很多示例程序里面默认的收包队列长度是128,这就是表示为每一个收包队列都分配128个收包描述符,这是一个适应大多数场景的经验值。但是在某些更高速率的网卡收包的情况下,128就可能不一定够了,或者在某些场景下发现丢包现象比较容易的时候,就需要考虑使用更长的收包队列,例如可以使用512或者1024。
- 发包队列长度:DPDK的示例程序里面默认的发包队列长度使用的是512,这就表示为每一个发包队列都分配512个发包描述符,这是一个适用大部分场合的经验值。当处理更高速率的网卡设备时,或者发现有丢包的时候,就应该考虑更长的发包队列,例如1024。
- 收包队列可释放描述符数量阈值(rx_free_thresh):DPDK驱动程序并没有每次收包都更新收包队列尾部索引寄存器,而是在可释放的收包描述符数量达到一个阈值(rx_free_thresh)的时候才真正更新收包队列尾部索引寄存器。这个可释放收包描述符数量阈值在驱动程序里面的默认值一般都是32,在示例程序里面,有的会设置成用户可配参数,可能设置成不同的默认值,例如64或者其他。设置合适的可释放描述符数量阈值,可以减少没有必要的过多的收包队列尾部索引寄存器的访问,改善收包的性能。
- 发包队列发送结果报告阈值(tx_rs_thresh):这个阈值的存在允许软件在配置发包描述符的同时设定一个回写标记,只有设置了回写标记的发包描述符硬件才会在发包完成后产生写回的动作,并且这个回写标记是设置在一定间隔(阈值)的发包描述符上。这个机制可以减少不必要的回写的次数,从而能够改善性能。
- 发包描述符释放阈值(tx_free_thresh):在DPDK驱动程序里面,默认值是32,用户可能需要根据实际使用的队列长度来调整。发包描述符释放阈值设置得过大,则可能描述符释放的动作很频繁发生,影响性能;发包描述符释放阈值设置过小,则可能每一次集中释放描述符的时候耗时较多,来不及提供新的可用的发包描述符给发包函数使用,甚至造成丢包。