etcd
Etcd 是 CoreOS 基于 Raft 开发的分布式 key-value 存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。
Etcd 主要功能
- 基本的 key-value 存储
- 监听机制
- key 的过期及续约机制,用于监控和服务发现
- 原子 CAS 和 CAD,用于分布式锁和 leader 选举
Etcd 基于 RAFT 的一致性
选举方法
- 1) 初始启动时,节点处于 follower 状态并被设定一个 election timeout,如果在这一时间周期内没有收到来自 leader 的 heartbeat,节点将发起选举:将自己切换为 candidate 之后,向集群中其它 follower 节点发送请求,询问其是否选举自己成为 leader。
- 2) 当收到来自集群中过半数节点的接受投票后,节点即成为 leader,开始接收保存 client 的数据并向其它的 follower 节点同步日志。如果没有达成一致,则 candidate 随机选择一个等待间隔(150ms ~ 300ms)再次发起投票,得到集群中半数以上 follower 接受的 candidate 将成为 leader
- 3) leader 节点依靠定时向 follower 发送 heartbeat 来保持其地位。
- 4) 任何时候如果其它 follower 在 election timeout 期间都没有收到来自 leader 的 heartbeat,同样会将自己的状态切换为 candidate 并发起选举。每成功选举一次,新 leader 的任期(Term)都会比之前 leader 的任期大 1。
日志复制
当前 Leader 收到客户端的日志(事务请求)后先把该日志追加到本地的 Log 中,然后通过 heartbeat 把该 Entry 同步给其他 Follower,Follower 接收到日志后记录日志然后向 Leader 发送 ACK,当 Leader 收到大多数(n/2+1)Follower 的 ACK 信息后将该日志设置为已提交并追加到本地磁盘中,通知客户端并在下个 heartbeat 中 Leader 将通知所有的 Follower 将该日志存储在自己的本地磁盘中。
安全性
安全性是用于保证每个节点都执行相同序列的安全机制,如当某个 Follower 在当前 Leader commit Log 时变得不可用了,稍后可能该 Follower 又会被选举为 Leader,这时新 Leader 可能会用新的 Log 覆盖先前已 committed 的 Log,这就是导致节点执行不同序列;Safety 就是用于保证选举出来的 Leader 一定包含先前 committed Log 的机制;
- 选举安全性(Election Safety):每个任期(Term)只能选举出一个 Leader
- Leader 完整性(Leader Completeness):指 Leader 日志的完整性,当 Log 在任期 Term1 被 Commit 后,那么以后任期 Term2、Term3… 等的 Leader 必须包含该 Log;Raft 在选举阶段就使用 Term 的判断用于保证完整性:当请求投票的该 Candidate 的 Term 较大或 Term 相同 Index 更大则投票,否则拒绝该请求。
失效处理
- 1) Leader 失效:其他没有收到 heartbeat 的节点会发起新的选举,而当 Leader 恢复后由于步进数小会自动成为 follower(日志也会被新 leader 的日志覆盖)
- 2)follower 节点不可用:follower 节点不可用的情况相对容易解决。因为集群中的日志内容始终是从 leader 节点同步的,只要这一节点再次加入集群时重新从 leader 节点处复制日志即可。
- 3)多个 candidate:冲突后 candidate 将随机选择一个等待间隔(150ms ~ 300ms)再次发起投票,得到集群中半数以上 follower 接受的 candidate 将成为 leader
wal 日志
Etcd 实现 raft 的时候,充分利用了 go 语言 CSP 并发模型和 chan 的魔法,想更进行一步了解的可以去看源码,这里只简单分析下它的 wal 日志。

wal 日志是二进制的,解析出来后是以上数据结构 LogEntry。其中第一个字段 type,只有两种,一种是 0 表示 Normal,1 表示 ConfChange(ConfChange 表示 Etcd 本身的配置变更同步,比如有新的节点加入等)。第二个字段是 term,每个 term 代表一个主节点的任期,每次主节点变更 term 就会变化。第三个字段是 index,这个序号是严格有序递增的,代表变更序号。第四个字段是二进制的 data,将 raft request 对象的 pb 结构整个保存下。Etcd 源码下有个 tools/etcd-dump-logs,可以将 wal 日志 dump 成文本查看,可以协助分析 raft 协议。
raft 协议本身不关心应用数据,也就是 data 中的部分,一致性都通过同步 wal 日志来实现,每个节点将从主节点收到的 data apply 到本地的存储,raft 只关心日志的同步状态,如果本地存储实现的有 bug,比如没有正确的将 data apply 到本地,也可能会导致数据不一致。
Etcd v2 与 v3
Etcd v2 和 v3 本质上是共享同一套 raft 协议代码的两个独立的应用,接口不一样,存储不一样,数据互相隔离。也就是说如果从 Etcd v2 升级到 Etcd v3,原来 v2 的数据还是只能用 v2 的接口访问,v3 的接口创建的数据也只能访问通过 v3 的接口访问。所以我们按照 v2 和 v3 分别分析。
推荐在 Kubernetes 集群中使用 Etcd v3,v2 版本已在 Kubernetes v1.11 中弃用。
Etcd v2 存储,Watch 以及过期机制
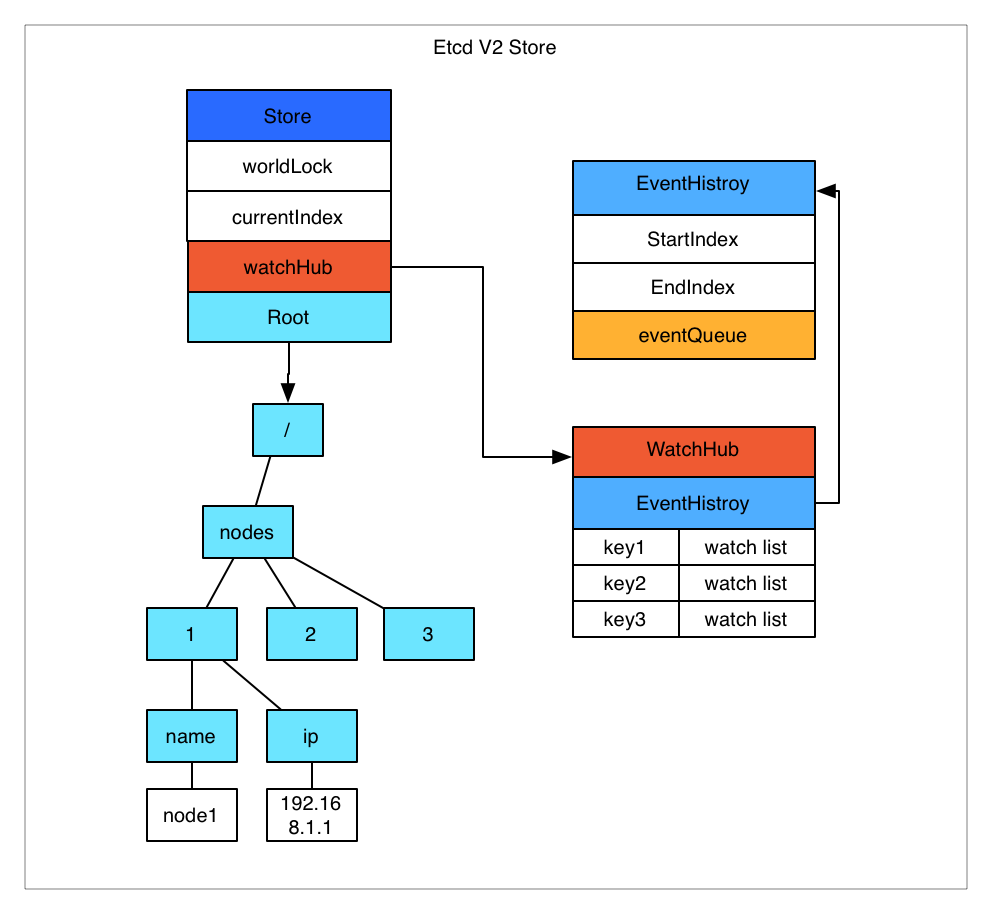
Etcd v2 是个纯内存的实现,并未实时将数据写入到磁盘,持久化机制很简单,就是将 store 整合序列化成 json 写入文件。数据在内存中是一个简单的树结构。比如以下数据存储到 Etcd 中的结构就如图所示。
/nodes/1/name node1
/nodes/1/ip 192.168.1.1
store 中有一个全局的 currentIndex,每次变更,index 会加 1. 然后每个 event 都会关联到 currentIndex.
当客户端调用 watch 接口(参数中增加 wait 参数)时,如果请求参数中有 waitIndex,并且 waitIndex 小于 currentIndex,则从 EventHistroy 表中查询 index 大于等于 waitIndex,并且和 watch key 匹配的 event,如果有数据,则直接返回。如果历史表中没有或者请求没有带 waitIndex,则放入 WatchHub 中,每个 key 会关联一个 watcher 列表。 当有变更操作时,变更生成的 event 会放入 EventHistroy 表中,同时通知和该 key 相关的 watcher。
这里有几个影响使用的细节问题:
- EventHistroy 是有长度限制的,最长 1000。也就是说,如果你的客户端停了许久,然后重新 watch 的时候,可能和该 waitIndex 相关的 event 已经被淘汰了,这种情况下会丢失变更。
- 如果通知 watcher 的时候,出现了阻塞(每个 watcher 的 channel 有 100 个缓冲空间),Etcd 会直接把 watcher 删除,也就是会导致 wait 请求的连接中断,客户端需要重新连接。
- Etcd store 的每个 node 中都保存了过期时间,通过定时机制进行清理。
从而可以看出,Etcd v2 的一些限制:
- 过期时间只能设置到每个 key 上,如果多个 key 要保证生命周期一致则比较困难。
- watcher 只能 watch 某一个 key 以及其子节点(通过参数 recursive),不能进行多个 watch。
- 很难通过 watch 机制来实现完整的数据同步(有丢失变更的风险),所以当前的大多数使用方式是通过 watch 得知变更,然后通过 get 重新获取数据,并不完全依赖于 watch 的变更 event。
Etcd v3 存储,Watch 以及过期机制
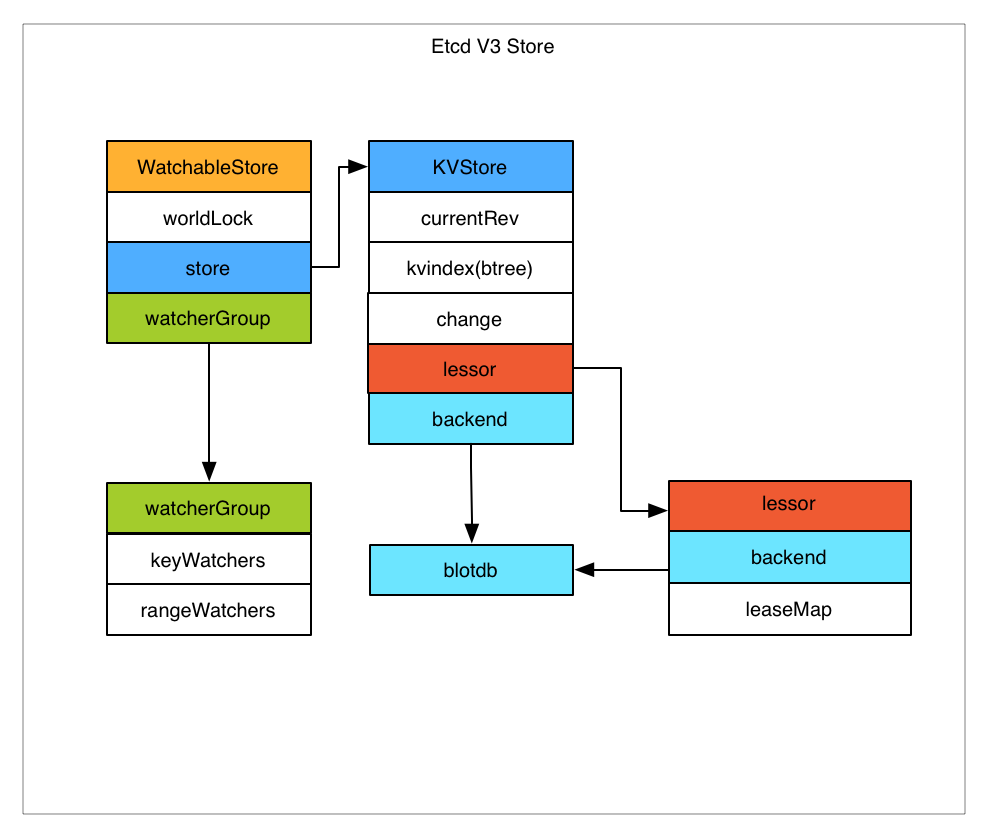
Etcd v3 将 watch 和 store 拆开实现,我们先分析下 store 的实现。
Etcd v3 store 分为两部分,一部分是内存中的索引,kvindex,是基于 google 开源的一个 golang 的 btree 实现的,另外一部分是后端存储。按照它的设计,backend 可以对接多种存储,当前使用的 boltdb。boltdb 是一个单机的支持事务的 kv 存储,Etcd 的事务是基于 boltdb 的事务实现的。Etcd 在 boltdb 中存储的 key 是 revision,value 是 Etcd 自己的 key-value 组合,也就是说 Etcd 会在 boltdb 中把每个版本都保存下,从而实现了多版本机制。
举个例子: 用 etcdctl 通过批量接口写入两条记录:
etcdctl txn <<<'
put key1 "v1"
put key2 "v2"
'
再通过批量接口更新这两条记录:
etcdctl txn <<<'
put key1 "v12"
put key2 "v22"
'
boltdb 中其实有了 4 条数据:
rev={3 0}, key=key1, value="v1"
rev={3 1}, key=key2, value="v2"
rev={4 0}, key=key1, value="v12"
rev={4 1}, key=key2, value="v22"
revision 主要由两部分组成,第一部分 main rev,每次事务进行加一,第二部分 sub rev,同一个事务中的每次操作加一。如上示例,第一次操作的 main rev 是 3,第二次是 4。当然这种机制大家想到的第一个问题就是空间问题,所以 Etcd 提供了命令和设置选项来控制 compact,同时支持 put 操作的参数来精确控制某个 key 的历史版本数。
了解了 Etcd 的磁盘存储,可以看出如果要从 boltdb 中查询数据,必须通过 revision,但客户端都是通过 key 来查询 value,所以 Etcd 的内存 kvindex 保存的就是 key 和 revision 之前的映射关系,用来加速查询。
然后我们再分析下 watch 机制的实现。Etcd v3 的 watch 机制支持 watch 某个固定的 key,也支持 watch 一个范围(可以用于模拟目录的结构的 watch),所以 watchGroup 包含两种 watcher,一种是 key watchers,数据结构是每个 key 对应一组 watcher,另外一种是 range watchers, 数据结构是一个 IntervalTree(不熟悉的参看文文末链接),方便通过区间查找到对应的 watcher。
同时,每个 WatchableStore 包含两种 watcherGroup,一种是 synced,一种是 unsynced,前者表示该 group 的 watcher 数据都已经同步完毕,在等待新的变更,后者表示该 group 的 watcher 数据同步落后于当前最新变更,还在追赶。
当 Etcd 收到客户端的 watch 请求,如果请求携带了 revision 参数,则比较请求的 revision 和 store 当前的 revision,如果大于当前 revision,则放入 synced 组中,否则放入 unsynced 组。同时 Etcd 会启动一个后台的 goroutine 持续同步 unsynced 的 watcher,然后将其迁移到 synced 组。也就是这种机制下,Etcd v3 支持从任意版本开始 watch,没有 v2 的 1000 条历史 event 表限制的问题(当然这是指没有 compact 的情况下)。
另外我们前面提到的,Etcd v2 在通知客户端时,如果网络不好或者客户端读取比较慢,发生了阻塞,则会直接关闭当前连接,客户端需要重新发起请求。Etcd v3 为了解决这个问题,专门维护了一个推送时阻塞的 watcher 队列,在另外的 goroutine 里进行重试。
Etcd v3 对过期机制也做了改进,过期时间设置在 lease 上,然后 key 和 lease 关联。这样可以实现多个 key 关联同一个 lease id,方便设置统一的过期时间,以及实现批量续约。
相比 Etcd v2, Etcd v3 的一些主要变化:
- 接口通过 grpc 提供 rpc 接口,放弃了 v2 的 http 接口。优势是长连接效率提升明显,缺点是使用不如以前方便,尤其对不方便维护长连接的场景。
- 废弃了原来的目录结构,变成了纯粹的 kv,用户可以通过前缀匹配模式模拟目录。
- 内存中不再保存 value,同样的内存可以支持存储更多的 key。
- watch 机制更稳定,基本上可以通过 watch 机制实现数据的完全同步。
- 提供了批量操作以及事务机制,用户可以通过批量事务请求来实现 Etcd v2 的 CAS 机制(批量事务支持 if 条件判断)。
Etcd,Zookeeper,Consul 比较
- Etcd 和 Zookeeper 提供的能力非常相似,都是通用的一致性元信息存储,都提供 watch 机制用于变更通知和分发,也都被分布式系统用来作为共享信息存储,在软件生态中所处的位置也几乎是一样的,可以互相替代的。二者除了实现细节,语言,一致性协议上的区别,最大的区别在周边生态圈。Zookeeper 是 apache 下的,用 java 写的,提供 rpc 接口,最早从 hadoop 项目中孵化出来,在分布式系统中得到广泛使用(hadoop, solr, kafka, mesos 等)。Etcd 是 coreos 公司旗下的开源产品,比较新,以其简单好用的 rest 接口以及活跃的社区俘获了一批用户,在新的一些集群中得到使用(比如 kubernetes)。虽然 v3 为了性能也改成二进制 rpc 接口了,但其易用性上比 Zookeeper 还是好一些。
- 而 Consul 的目标则更为具体一些,Etcd 和 Zookeeper 提供的是分布式一致性存储能力,具体的业务场景需要用户自己实现,比如服务发现,比如配置变更。而 Consul 则以服务发现和配置变更为主要目标,同时附带了 kv 存储。
Etcd 的周边工具
Confd
在分布式系统中,理想情况下是应用程序直接和 Etcd 这样的服务发现 / 配置中心交互,通过监听 Etcd 进行服务发现以及配置变更。但我们还有许多历史遗留的程序,服务发现以及配置大多都是通过变更配置文件进行的。Etcd 自己的定位是通用的 kv 存储,所以并没有像 Consul 那样提供实现配置变更的机制和工具,而 Confd 就是用来实现这个目标的工具。
Confd 通过 watch 机制监听 Etcd 的变更,然后将数据同步到自己的一个本地存储。用户可以通过配置定义自己关注哪些 key 的变更,同时提供一个配置文件模板。Confd 一旦发现数据变更就使用最新数据渲染模板生成配置文件,如果新旧配置文件有变化,则进行替换,同时触发用户提供的 reload 脚本,让应用程序重新加载配置。
Confd 相当于实现了部分 Consul 的 agent 以及 consul-template 的功能,作者是 kubernetes 的 Kelsey Hightower,但大神貌似很忙,没太多时间关注这个项目了,很久没有发布版本,我们着急用,所以 fork 了一份自己更新维护,主要增加了一些新的模板函数以及对 metad 后端的支持。confd
Metad
服务注册的实现模式一般分为两种,一种是调度系统代为注册,一种是应用程序自己注册。调度系统代为注册的情况下,应用程序启动后需要有一种机制让应用程序知道『我是谁』,然后发现自己所在的集群以及自己的配置。Metad 提供这样一种机制,客户端请求 Metad 的一个固定的接口 /self,由 Metad 告知应用程序其所属的元信息,简化了客户端的服务发现和配置变更逻辑。
Metad 通过保存一个 ip 到元信息路径的映射关系来做到这一点,当前后端支持 Etcd v3,提供简单好用的 http rest 接口。 它会把 Etcd 的数据通过 watch 机制同步到本地内存中,相当于 Etcd 的一个代理。所以也可以把它当做 Etcd 的代理来使用,适用于不方便使用 Etcd v3 的 rpc 接口或者想降低 Etcd 压力的场景。 metad
Etcd 使用注意事项
Etcd cluster 初始化的问题
如果集群第一次初始化启动的时候,有一台节点未启动,通过 v3 的接口访问的时候,会报告 Error: Etcdserver: not capable 错误。这是为兼容性考虑,集群启动时默认的 API 版本是 2.3,只有当集群中的所有节点都加入了,确认所有节点都支持 v3 接口时,才提升集群版本到 v3。这个只有第一次初始化集群的时候会遇到,如果集群已经初始化完毕,再挂掉节点,或者集群关闭重启(关闭重启的时候会从持久化数据中加载集群 API 版本),都不会有影响。
Etcd 读请求的机制
v2 quorum=true 的时候,读取是通过 raft 进行的,通过 cli 请求,该参数默认为 true。
v3 --consistency=“l” 的时候(默认)通过 raft 读取,否则读取本地数据。sdk 代码里则是通过是否打开:WithSerializable option 来控制。
一致性读取的情况下,每次读取也需要走一次 raft 协议,能保证一致性,但性能有损失,如果出现网络分区,集群的少数节点是不能提供一致性读取的。但如果不设置该参数,则是直接从本地的 store 里读取,这样就损失了一致性。使用的时候需要注意根据应用场景设置这个参数,在一致性和可用性之间进行取舍。
Etcd 的 compact 机制
Etcd 默认不会自动 compact,需要设置启动参数,或者通过命令进行 compact,如果变更频繁建议设置,否则会导致空间和内存的浪费以及错误。Etcd v3 的默认的 backend quota 2GB,如果不 compact,boltdb 文件大小超过这个限制后,就会报错:”Error: etcdserver: mvcc: database space exceeded”,导致数据无法写入。
etcd 的问题
当前 Etcd 的 raft 实现保证了多个节点数据之间的同步,但明显的一个问题就是扩充节点不能解决容量问题。要想解决容量问题,只能进行分片,但分片后如何使用 raft 同步数据?只能实现一个 multiple group raft,每个分片的多个副本组成一个虚拟的 raft group,通过 raft 实现数据同步。当前实现了 multiple group raft 的有 TiKV 和 Cockroachdb,但尚未一个独立通用的。理论上来说,如果有了这套 multiple group raft,后面挂个持久化的 kv 就是一个分布式 kv 存储,挂个内存 kv 就是分布式缓存,挂个 lucene 就是分布式搜索引擎。当然这只是理论上,要真实现复杂度还是不小。